Minimum Bounding Sphere for Frustum
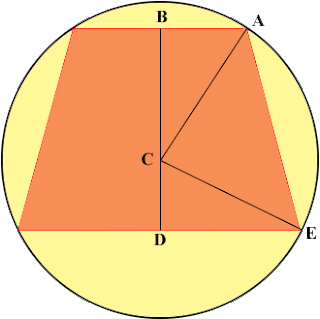
I was in need to create a minimum bounding sphere for a frustum (truncated pyramid). The easiest way is to find the "center" of this pyramid. I got it by calculating the middle point of "the center of the near plane" and "the center of the far plane". The radius will be the length between this middle point and one of the vertices of the far plane. This works however, this is not an optimal bounding sphere for frustum. I sat down and tried to figure out this problem. It turns out there is a simple way of doing this. Since the frustum is created with perspective projection in mind, this frustum is symmetrical. Furthermore, if we temporarily forget about the aspect ratio, the problem can be reduced into 2D problem: " Given an isosceles trapezoid, find the circumscribed circle ". I got the image from http://mathcentral.uregina.ca/QQ/database/QQ.09.09/h/abby1.html. The first thing to realize is that the center of the enclosing circle is the inters...